


This post is co-written with Eliuth Triana, Abhishek Sawarkar, Jiahong Liu, Kshitiz Gupta, JR Morgan and Deepika Padmanabhan from NVIDIA.
At the 2024 NVIDIA GTC conference, we announced support for NVIDIA NIM Inference Microservices in Amazon SageMaker Inference. This integration allows you to deploy industry-leading large language models (LLMs) on SageMaker and optimize their performance and cost. The optimized prebuilt containers enable the deployment of state-of-the-art LLMs in minutes instead of days, facilitating their seamless integration into enterprise-grade AI applications.
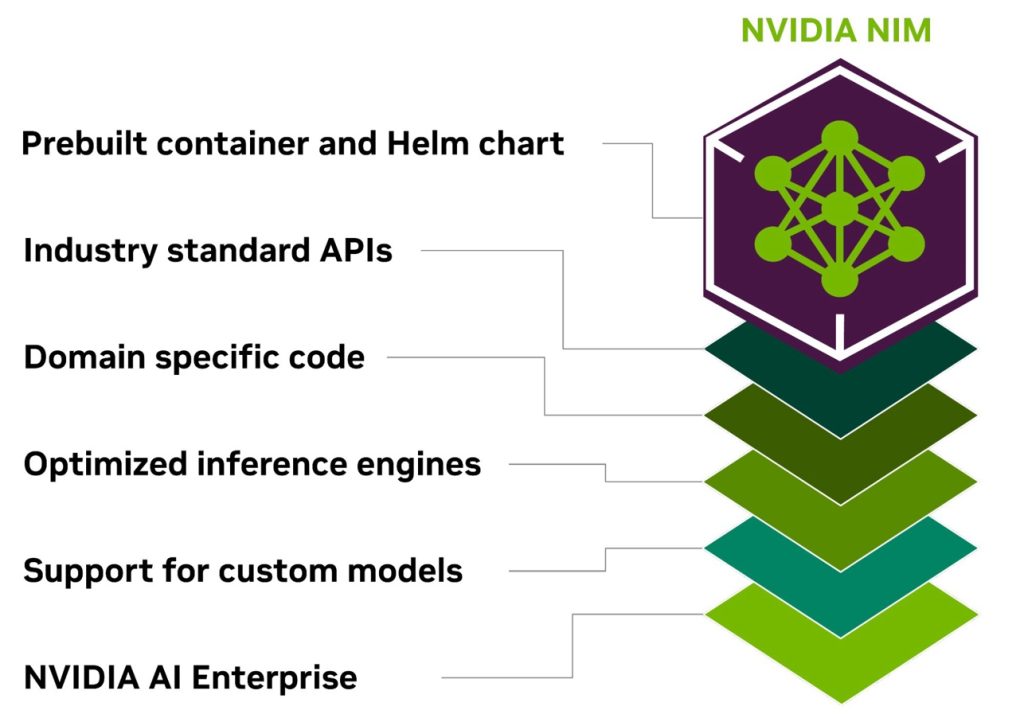
NIM is built on technologies like NVIDIA TensorRT, NVIDIA TensorRT-LLM, and vLLM. NIM is engineered to enable straightforward, secure, and performant AI inferencing on NVIDIA GPU-accelerated instances hosted by SageMaker. This allows developers to take advantage of the power of these advanced models using SageMaker APIs and just a few lines of code, accelerating the deployment of cutting-edge AI capabilities within their applications.
NIM, part of the NVIDIA AI Enterprise software platform listed on AWS Marketplace, is a set of inference microservices that bring the power of state-of-the-art LLMs to your applications, providing natural language processing (NLP) and understanding capabilities, whether you’re developing chatbots, summarizing documents, or implementing other NLP-powered applications. You can use pre-built NVIDIA containers to host popular LLMs that are optimized for specific NVIDIA GPUs for quick deployment. Companies like Amgen, A-Alpha Bio, Agilent, and Hippocratic AI are among those using NVIDIA AI on AWS to accelerate computational biology, genomics analysis, and conversational AI.
In this post, we provide a walkthrough of how customers can use generative artificial intelligence (AI) models and LLMs using NVIDIA NIM integration with SageMaker. We demonstrate how this integration works and how you can deploy these state-of-the-art models on SageMaker, optimizing their performance and cost.
You can use the optimized pre-built NIM containers to deploy LLMs and integrate them into your enterprise-grade AI applications built with SageMaker in minutes, rather than days. We also share a sample notebook that you can use to get started, showcasing the simple APIs and few lines of code required to harness the capabilities of these advanced models.
Solution overview
Getting started with NIM is straightforward. Within the NVIDIA API catalog, developers have access to a wide range of NIM optimized AI models that you can use to build and deploy your own AI applications. You can get started with prototyping directly in the catalog using the GUI (as shown in the following screenshot) or interact directly with the API for free.
To deploy NIM on SageMaker, you need to download NIM and subsequently deploy it. You can initiate this process by choosing Run Anywhere with NIM for the model of your choice, as shown in the following screenshot.
You can sign up for the free 90-day evaluation license on the API Catalog by signing up with your organization email address. This will grant you a personal NGC API key for pulling the assets from NGC and running on SageMaker. For pricing details on SageMaker, refer to Amazon SageMaker pricing.
Prerequisites
As a prerequisite, set up an Amazon SageMaker Studio environment:
Make sure the existing SageMaker domain has Docker access enabled. If not, run the following command to update the domain:
After Docker access is enabled for the domain, create a user profile by running the following command:
Create a JupyterLab space for the user profile you created.
After you create the JupyterLab space, run the following bash script to install the Docker CLI.
Set up your Jupyter notebook environment
For this series of steps, we use a SageMaker Studio JupyterLab notebook. You also need to attach an Amazon Elastic Block Store (Amazon EBS) volume of at least 300 MB in size, which you can do in the domain settings for SageMaker Studio. In this example, we use an ml.g5.4xlarge instance, powered by a NVIDIA A10G GPU.
We start by opening the example notebook provided on our JupyterLab instance, import the corresponding packages, and set up the SageMaker session, role, and account information:
Pull the NIM container from the public container to push it to your private container
The NIM container that comes with SageMaker integration built in is available in the Amazon ECR Public Gallery. To deploy it on your own SageMaker account securely, you can pull the Docker container from the public Amazon Elastic Container Registry (Amazon ECR) container maintained by NVIDIA and re-upload it to your own private container:
Set up the NVIDIA API key
NIMs can be accessed using the NVIDIA API catalog. You just need to register for an NVIDIA API key from the NGC catalog by choosing Generate Personal Key.
When creating an NGC API key, choose at least NGC Catalog on the Services Included dropdown menu. You can include more services if you plan to reuse this key for other purposes.
For the purposes of this post, we store it in an environment variable:
NGC_API_KEY = YOUR_KEY
This key is used to download pre-optimized model weights when running the NIM.
Create your SageMaker endpoint
We now have all the resources prepared to deploy to a SageMaker endpoint. Using your notebook after setting up your Boto3 environment, you first need to make sure you reference the container you pushed to Amazon ECR in an earlier step:
After the model definition is set up correctly, the next step is to define the endpoint configuration for deployment. In this example, we deploy the NIM on one ml.g5.4xlarge instance:
Lastly, create the SageMaker endpoint:
Run inference against the SageMaker endpoint with NIM
After the endpoint is deployed successfully, you can run requests against the NIM-powered SageMaker endpoint using the REST API to try out different questions and prompts to interact with the generative AI models:
That’s it! You now have an endpoint in service using NIM on SageMaker.
NIM licensing
NIM is part of the NVIDIA Enterprise License. NIM comes with a 90-day evaluation license to start with. To use NIMs on SageMaker beyond the 90-day license, connect with NVIDIA for AWS Marketplace private pricing. NIM is also available as a paid offering as part of the NVIDIA AI Enterprise software subscription available on AWS Marketplace
Conclusion
In this post, we showed you how to get started with NIM on SageMaker for pre-built models. Feel free to try it out following the example notebook.
We encourage you to explore NIM to adopt it to benefit your own use cases and applications.
About the Authors
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time, he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends. You can find him on LinkedIn.
Qing Lan is a Software Development Engineer in AWS. He has been working on several challenging products in Amazon, including high performance ML inference solutions and high-performance logging systems. Qing’s team successfully launched the first billion-parameter model in Amazon Advertising with very low latency required. Qing has in-depth knowledge on infrastructure optimization and deep learning acceleration.
Raghu Ramesha is a Senior GenAI/ML Solutions Architect on the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in computer science from UT Dallas. In his free time, he enjoys traveling and photography.
Eliuth Triana is a Developer Relations Manager at NVIDIA empowering Amazon’s AI MLOps, DevOps, Scientists and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing Generative AI Foundation models spanning from data curation, GPU training, model inference and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, tennis and poker player.
Abhishek Sawarkar is a product manager in the NVIDIA AI Enterprise team working on integrating NVIDIA AI Software in Cloud MLOps platforms. He focuses on integrating the NVIDIA AI end-to-end stack within Cloud platforms & enhancing user experience on accelerated computing.
Jiahong Liu is a Solutions Architect on the Cloud Service Provider team at NVIDIA. He assists clients in adopting machine learning and AI solutions that leverage NVIDIA-accelerated computing to address their training and inference challenges. In his leisure time, he enjoys origami, DIY projects, and playing basketball.
Kshitiz Gupta is a Solutions Architect at NVIDIA. He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deep learning applications. Outside of work, he enjoys running, hiking, and wildlife watching.
JR Morgan is a Principal Technical Product Manager in NVIDIA’s Enterprise Product Group, thriving at the intersection of partner services, APIs, and open source. After work, he can be found on a Gixxer, at the beach, or spending time with his amazing family.
Deepika Padmanabhan is a Solutions Architect at NVIDIA. She enjoys building and deploying NVIDIA’s software solutions in the cloud. Outside work, she enjoys solving puzzles and playing video games like Age of Empires.
